
CAN报文
前言
一直都不会根据CANDBC的LAYOUT写结构体,每次接到需要修改结构体的需求,都是应付先把任务完成;这件事一直是我的一个心病,因为我根本不懂原理,非常难受。趁着这次客户的DBC原始数据是Intel模式,把这些知识搞清楚。
大小端
在计算机科学和技术中,大小端是指在存储和传输数据时字节序列的顺序;
计算机中的所有数据都以二进制位的形式进行存储,并且每8个二进制位组成一个字节;因此,一段数据可以看作是由若干个字节组成的;而字节序列则是由多个字节组成的二进制数据,在存储和传输数据时,字节序列的排列方式会影响到程序的正确性、可读性以及跨平台兼容性等问题;
大端模式是指将高序位字节存储在起始地址,而小端模式则是指将低序位字节存储在起始地址;对于一个四字节整数0x12345678,大小端的存储方式如下所示;
| 地址 | 0x1 | 0x2 | 0x3 | 0x4 |
|---|---|---|---|---|
| 大端模式 | 0x12 | 0x34 | 0x56 | 0x78 |
| 小端模式 | 0x78 | 0x56 | 0x34 | 0x12 |
在大端模式下,高字节存储在低地址,低字节存储在高地址;在小端模式下,低字节存储在低地址,高字节存储在高地址;
位域
C 语言的位域是一种特殊的结构体成员,允许我们按位对成员进行定义,指定其占用的位数;位域总是从低位开始,高位结束;
1 | typedef union |
如上面代码所示,CAN_Prefill占据八位中的低四位,CAN_ParkingMode占据八位中的高四位;
CAN报文位序与字节序
CAN报文的位序为大端模式,即高位存储在bit7,低位存储在bit0;而CAN报文的字节序可以分为Intel模式(小端)和Motorola(大端)两种模式;CAN传输的顺序是Byte0-Byte7,bit7-bit0,这个传输顺序应该是CAN2.0的标准(为什么是应该,因为我自己没看CAN2.0标准,网上这么说的);
Intel模式
Intel模式是小端模式,在跨字节时,低位存储在低字节的低位,高位存储在高字节的高位;对于一个数据0x3E8按照英特尔模式存储,存储数据的顺序如下图所示(存入下图蓝色占据10个bit的变量中),0x3E8的二进制为001111101000;如果将存储方式的数据拼凑成我们正常的书写顺序,需要将Byte3的bit1和bit0移至Byte2的bit7前面,即是0X3E8的二进制;

因此当通过上图的变量向MCU传输0x3E8数据时,CAN传输的数据为0xE803(CAN传输顺序决定如此);由于我使用的是NXP MC9S12ZVM芯片,是大端存储,因此,MCU在接收到这个数据时,需要对数据进行处理;下面是接收这个CAN信号时的结构体,LOW的数据为0xE8,High的数据为0x03,要将这两个数据拼凑成0x3E8,应该这么处理Pressure=(uint16_t)((((uint16_t)CAN_HMI.High)&0x03)<<8 + ((uint16_t)CAN_HMI.Low),这样才是我们需要的数据;
1 | typedef union |
在我对此一无所知的时候,我试图寻找一种通过位域的方式能直接读取Intel模式的数据,而不需要对数据进行任何处理,当然均以失败告终;当跨字节时,将Intel模式的数据拼凑成我们正常书写的习惯的方法为将高字节的数据移至低字节高位的前面即可;
Motorola模式
Motorola模式是大端模式,在跨字节时,低位存储在高字节的低位,高位存储在低字节的高位;对于一个数据0x3E8按照英特尔模式存储(存入下图蓝色占据10个bit的变量中),存储数据的顺序如下图所示,0x3E8的二进制为001111101000;如果存储方式的数据拼凑成我们正常的书写顺序,需要将Byte2的bit7-bit5移至Byte1的bit0后面,其实Motorola模式的数据很符合书写习惯;
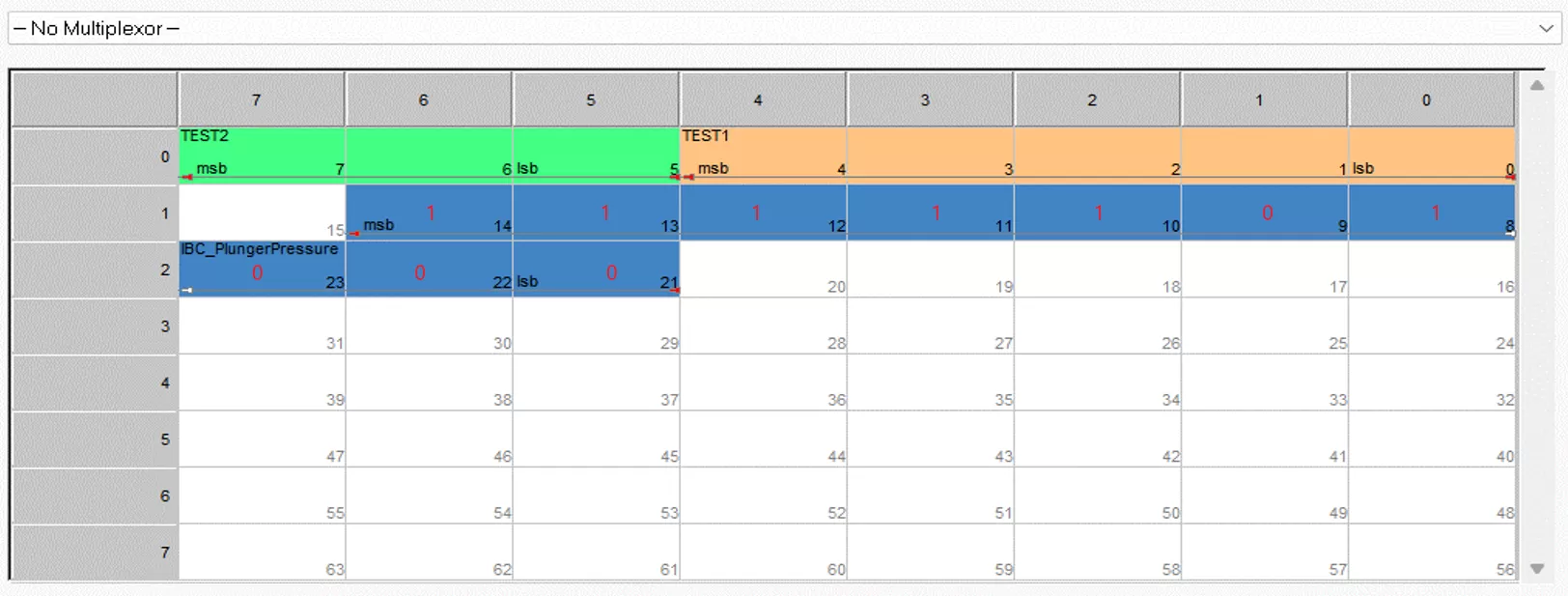
由于我使用的是NXP MC9S12ZVM芯片,是大端存储,CAN的位序为大端模式,Motorola模式又将字节序定义为大端模式,因此可以直接通过位域的方式获取数据;
1 | typedef union |
因此直接CAN_HMI.PRESSURE的数据即是我们需要的数据;
CAN报文的数据处理
我们经常会对CAN报文的数据进行加减乘除运算,那么做完加减乘除运算后的数据在传入MCU后会变成怎么样的数据呢,以下图的数据为例;
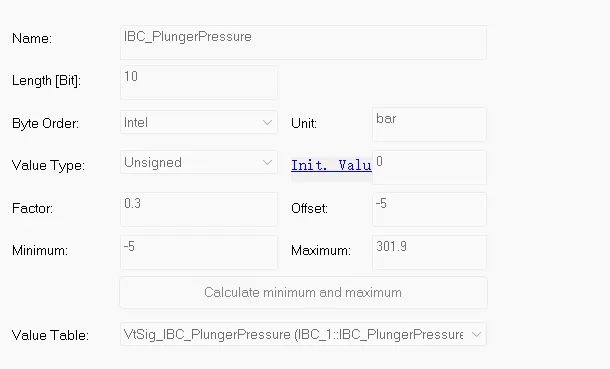
通过TSMaster将上图的变量设置为1时,MCU接收到的数据为20,即将(1-(-5)/0.3)=20
Simulink
如果实在是不想自己写位域,可以通过MATLAB的Simulink模块自动生成;